
Transform stranded power to AI-ready capacity that can be monetized
The Power Paradox
The AI boom is no longer just a story about large language model training and access to GPUs; it is increasingly a story about electricity. U.S. data center power demand jumped 22% last year and is forecast to nearly triple by 2030 (Source: S&P Global).
Yet a critical reality remains largely overlooked: Data centers are already wired for substantially more power than they consume.
A 2024 study reveals that 30–50% of installed power capacity in U.S. facilities sits unused (Source: LBNL). The consequence: enormous reservoirs of paid-for power capacity remain idle.
Source: Shehabi, A., et al. 2024 United States Data Center Energy Usage Report. Lawrence Berkeley National Laboratory, Berkeley, California. LBNL-2001637
As hyperscalers race to secure AI capacity, operators face a binary choice: build new gigawatt-scale facilities requiring multi-billion-dollar capital outlays and multi-year timelines, or unlock capacity already sitting idle.
The latter offers immediate deployment with zero grid constraints—reframing underutilization from a sunk cost into a massive source of value.
The Evidence: Underutilization is Systemic
Data centers are engineered with conservative buffers for rare worst-case scenarios, leaving massive reserves unutilized.
Facility-level Analysis: UK Data Centers
Analysis of 89 UK data centers—spanning both co-location and enterprise facilities—reveals a striking reality: even the best performers leave massive capacity on the table.
The highest-performing co-location facility operated at just 68% utilization, leaving 32% of contracted capacity stranded. The majority operated below 50%.
Monthly trends from January 2023 to June 2025 showed minimal variation, confirming that underutilization is chronic, structural, and systemic.
Co-location vs. Enterprise: Monthly Utilization Trends in UK Data Centers
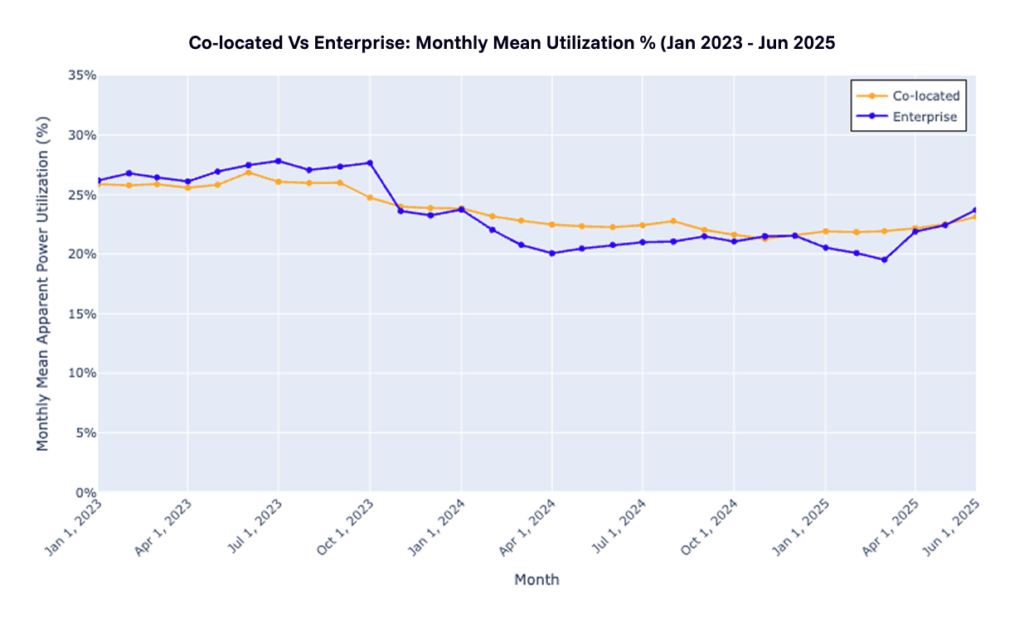
(Source: UK Power Networks)
What this Means at Scale
To contextualize this at scale: a 90 MW facility operating at 68% mean utilization harbors ~25 MW of stranded power—enough to power approximately 1,600 additional AI inference servers without any infrastructure expansion.
From Facility to Compute: The Problem Runs Deeper
The Pattern is Clear: Idle capacity is systemic across the data center stack – from power provisioning through compute allocation. Existing infrastructure could absorb substantially more AI workload without grid expansion.
The Opportunity: Latency-Tolerant AI Workloads
Not all AI is created equal. While real-time inference applications like chatbots demand instant responses, a vast and growing category of AI workloads is latency-tolerant—delivering full business value whether they complete in seconds, minutes, or hours.
This aligns with an ongoing market shift from training to inference. By 2028, more than 80% of workload accelerators deployed in data centers will be used to execute AI inference workloads (Source: Gartner). Latency-tolerant inference will comprise a substantial—and rapidly growing—share of this demand.
Examples of Latency-Tolerant AI Workloads

The strategic fit is perfect: Latency-critical workloads occupy peak windows, while flexible tasks absorb valley periods of idle capacity—resulting in higher utilization and lower marginal costs.
The challenge: How do we safely orchestrate these flexible tasks without compromising safety margins?
The Orchestration Imperative
Effectively tapping stranded power requires sophisticated orchestration across the entire data center stack—power systems, cooling infrastructure, compute resources, and workload scheduling.
Point solutions addressing single layers cannot capture the cross-layer interactions that determine true capacity headroom. The largest gains emerge from orchestrating all infrastructure as a single integrated system while maintaining safety margins and SLA commitments.
Why Hammerhead
Most orchestration platforms optimize individual layers in isolation. Hammerhead AI’s software-first platform orchestrates across the entire data center stack simultaneously—from on-site generation and storage systems through cooling infrastructure, IT equipment (racks, servers, GPUs), and AI workloads.

Hammerhead’s Orchestrated Reinforcement Learning Control Agent (ORCA) features autonomous, power-aware controllers that adapt in real-time, maximizing token throughput while enforcing operator-defined power guardrails and SLAs.
Business Impact:
- Data center operators: Convert slack capacity into AI revenue while serving core tenants and enabling flexible, non-firm capacity off-takers
- AI cloud providers: Access flexible capacity at lower cost per million tokens, optimally serving latency-tolerant workloads
- Enterprises: Expand AI using current colocation capacity, improving speed-to-market and reducing marginal deployment costs
- Data center OEMs: Differentiate offerings as AI-ready through Hammerhead partnerships
The Path Forward
The AI economy’s next breakthrough will be led by operators who unlock the power already sitting idle in existing infrastructure.
While industry conversation centers on grid constraints and power scarcity, 30-50% of provisioned data center power sits unused. Operators that seize this opportunity will slash marginal cost per AI token, avoid billion-dollar facility builds, and establish new benchmarks for sustainable growth.
The stranded power exists. The workloads are ready. The technology is proven.