
Use Stranded Megawatts for AI Inference Workloads.
Want the detailed numbers and playbook?
AI cloud and services providers, AI labs, and enterprises (collectively “AI inference companies”) keep hearing the same thing from data center operators: We are out of power.
At the same time, telemetry inside those same data centers shows GPUs idling and megawatts of capacity sitting unused. Power has become the main constraint for AI inference. However, in most environments, it is because the available power is not being optimized for use based on the type of AI workloads.
This is good news for AI companies. It means you do not have to wait years for new capacity to come online. You can deploy more GPUs, process more tokens, and generate new revenue from existing data centers. In our new whitepaper, “Faster and Cheaper Access to Power Capacity for AI Inference,” we share how Hammerhead’s power‑aware orchestration platform, ORCA and Dheyo’s GPU and workload optimization under power constraints enabled 30% more GPU capacity without increasing the existing power allocation.
The paradox: “power‑constrained” sites with idle capacity
Across hundreds of facilities, we see the same pattern:
- Mean power utilization often operates in the 20 – 30% range, even in “constrained” sites.
- GPUs serving production workloads spend most of their time at 0 – 30% utilization (Source: Hammerhead AI).
Why? Because data centers are engineered for rare worst‑case events: hot days, extreme load spikes, failures. The result is a large safety buffer between the power that is available and the power that is actually drawn.
This gap is stranded power, i.e., capacity that is available but not processing tokens or generating revenue. The tension between is exactly where the opportunity lies.
The unlock: treat workload segments differently
Not every workload needs the same treatment. Roughly, your inference traffic falls in three buckets: i) Low‑latency, ii) Latency‑tolerant, and iii) Throughput‑driven pipelines. The whitepaper shows that by explicitly segmenting workloads and treating latency-tolerant workloads differently, you can safely run more GPUs and process more tokens within the same power allocation.
Two levers: GPU modes + power‑aware orchestration
Workload‑aligned GPU modes (Dheyo): Dheyo analyzed large‑language‑model inference on NVIDIA H100, AMD MI300, and AMD MI325 GPUs and mapped GPU settings (batch size and frequency) into three practical “modes,” each tailored to a business use case:
- Cost‑optimized: Large batches, moderate frequency
- Ideal for batch summarization, synthetic data, offline analytics, and fine‑tuning
- Lowest cost per million tokens
- Low‑latency: Small batches, moderate frequency
- Ideal for chatbots, copilots, and user‑facing APIs
- Fastest responses, higher unit cost
- Max throughput: Large batches, high frequency
- Ideal for high‑volume internal pipelines
- Most tokens per second, highest power draw per GPU
Key takeaway: There is no single “best” GPU configuration. You get better economics by matching modes to workload types, not by applying one setting to all workload types.
Power‑aware orchestration (Hammerhead ORCA): Hammerhead ORCA sits one level above and monitors aggregate power usage across a facility, actively managing it in real time.
- ORCA continuously monitors aggregate IT power draw of incrementally new IT equipment and workloads.
- When usage approaches the facility’s fixed power allocation, ORCA selectively caps the incrementally new GPUs serving flexible workloads, reducing their power draw.
- Dheyo’s GPU and workload optimization layer processes and maximizes output for inference workloads under these power constraints.
- Existing customers and their low‑latency workloads remain untouched.
Together, these levers enable a simple but powerful outcome: If some of your workloads are latency-tolerant, ORCA can safely run more GPUs within the same power allocation, transforming stranded megawatts into AI‑ready capacity.
A Real-World Example: Same Power. 30+% More GPUs
In the whitepaper, we walk through a production‑grade proof of concept:
- NVIDIA H100 and AMD MI300 GPUs representing existing customer IT equipment, workloads, and SLAs.
- GPUs running Inference workloads, specifically text‑to‑video inference.
- A fixed power allocation that cannot be increased.
The question: Can we add 30% more GPU within the fixed power allocation?
Outcomes of the PoC:
- 30% more GPU capacity safely added.
- Existing workloads preserved: Original jobs keep their 70–75 second completion times.
- Latency-tolerant workloads absorbed the trade‑off: The new jobs run in 80–90 seconds, roughly 10–25% slower, and added 18–20% more throughput overall.
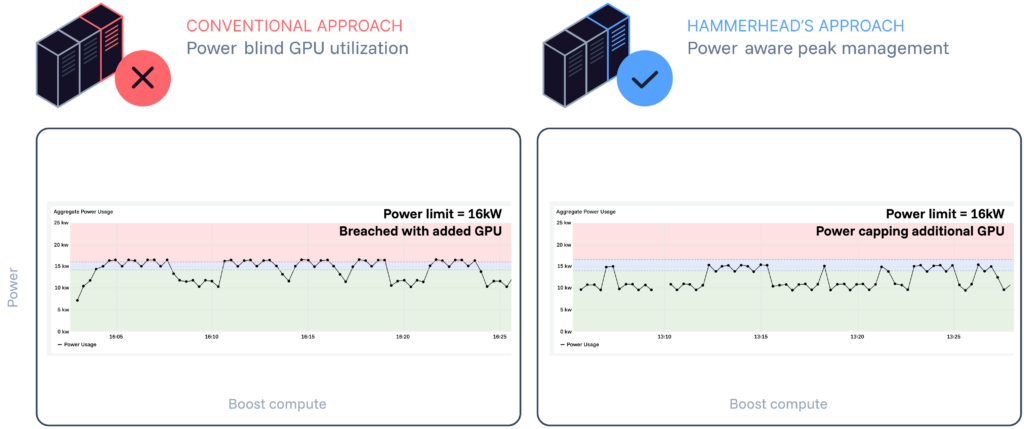
Figure 1: Results of PoC including power-aware orchestration by ORCA
Why does this matter for AI companies?
An AI inference company gets 30% more GPU capacity, more completed jobs, and more tokens per watt within the same power allocation with Hammerhead power-aware orchestration and Dheyo’s GPU and workload optimization under power constraints. Like Dheyo, any AI inference company may have their own GPU and workload optimization layer in their software stack that Hammerhead’s ORCA platform can integrate with to unlock 30% more AI compute capacity. This means:
- Faster access to capacity
- Rolling out ORCA across existing sites can unlock usable capacity in 6–9 months (driven by new IT hardware supply chain timelines), instead of waiting 3–5 years for new power and sites.
- Cheaper tokens for flexible workloads
- By running latency‑tolerant jobs on orchestrated capacity, up to 36% lower cost per million tokens can be achieved compared to standard capacity.
- This opens the door to new product SKUs for latency-tolerant Inference at a meaningfully lower price point for GPU-as-a-service providers.
- De-risked growth and improved ROI
- AI inference companies can defer multi‑billion‑dollar capex spending by first exhausting stranded capacity.
- Higher utilization of contracted power translates into better margins and more tokens per watt.
Read more in the full whitepaper
The blog can only scratch the surface. In the full whitepaper, we dive into:
- Three GPU serving modes optimized for types of workloads
- Detailed PoC results
- A step‑by‑step playbook for accessing AI-ready capacity faster and cheaper
- Token economics
If you’re running into power constraints, the fastest path to more AI capacity for inference workloads is sitting inside existing data centers. You can access this capacity through orchestration enabled by Hammerhead’s ORCA platform.